Vielen Dank, dass du uns auf dieser Forschungsreise begleitet hast. Wir hoffen, dass du einen Eindruck gewinnen konntest, wozu Künstliche Intelligenz in diesem Bereich schon fähig ist – und was noch nicht so gut klappt. Vielleicht kannst du jetzt sogar ChatGPT und andere Sprachmodelle besser erkennen?

In jeder Station haben wir ja ein Teil des Puzzles gesehen, wie sich menschliche und maschinelle Sprache ähneln oder unterscheiden – auch in Abhängigkeit von verschiedenen Sprachmodellen. Wir möchten dir nun einige weitere Informationen zu der Forschung geben, die den Aufgaben auf der Forschungsreise zu Grunde liegt.
Erklärungen und Konsequenzen für bewundern und amüsieren
Es ist dir bestimmt aufgefallen, dass wir es mal mit Fortsetzungen nach einem Satzkonnektor wie weil und mal mit solchen nach dem Konnektor sodass zu tun hatten. Was wir aber noch nicht besprochen haben, ist, dass wir auch verschiedene Klassen von Verben benutzt haben. Diese beiden Faktoren – Verbklasse und Satzkonnektor – haben nämlich einen entscheidenden Einfluss auf unsere Präferenzen, wie Menschen die Sätze bevorzugt fortsetzen.
Die Verben, die wir untersucht haben, beschreiben allesamt psychologische Relationen, wie etwa amüsieren und bewundern. Bei amüsieren löst das Subjekt des Satzes ein positives Gefühl im Objekt aus, während es bei bewundern das Albert ist, das ein Gefühl im Subjekt auslöst.
Hier folgen zwei typische Beispiele dafür, wie frühere Versuchsteilnehmer*innen Satzvorgaben nach weil und sodass fortgesetzt haben. Zuerst für amüsieren:
- Emma amüsierte Fritz, weil ... ✍ sie dauernd Witze erzählte.
- Emma amüsierte Fritz, sodass ... ✍ dieser sich noch etwas mehr Gin einschenkte.
Wie wir sehen, wird bei Erklärungen nach weil bevorzugt über das Subjekt (Emma) fortgesetzt, während Konsequenzen nach sodass eher etwas über das Objekt (Fritz) aussagen. Wir benutzen in der Forschung für solche systematischen Tendenzen das Wort Bias.
Bei bewundern ist dieses Muster genau umgekehrt: Erklärungen handeln vom Objekt (hier: Armin), Konsequenzen vom Subjekt:
- Anna bewunderte Armin, weil ... ✍ er so ein großes Herz hatte.
- Anna bewunderte Armin, sodass ... ✍ sie nach seinem Autogramm fragte.
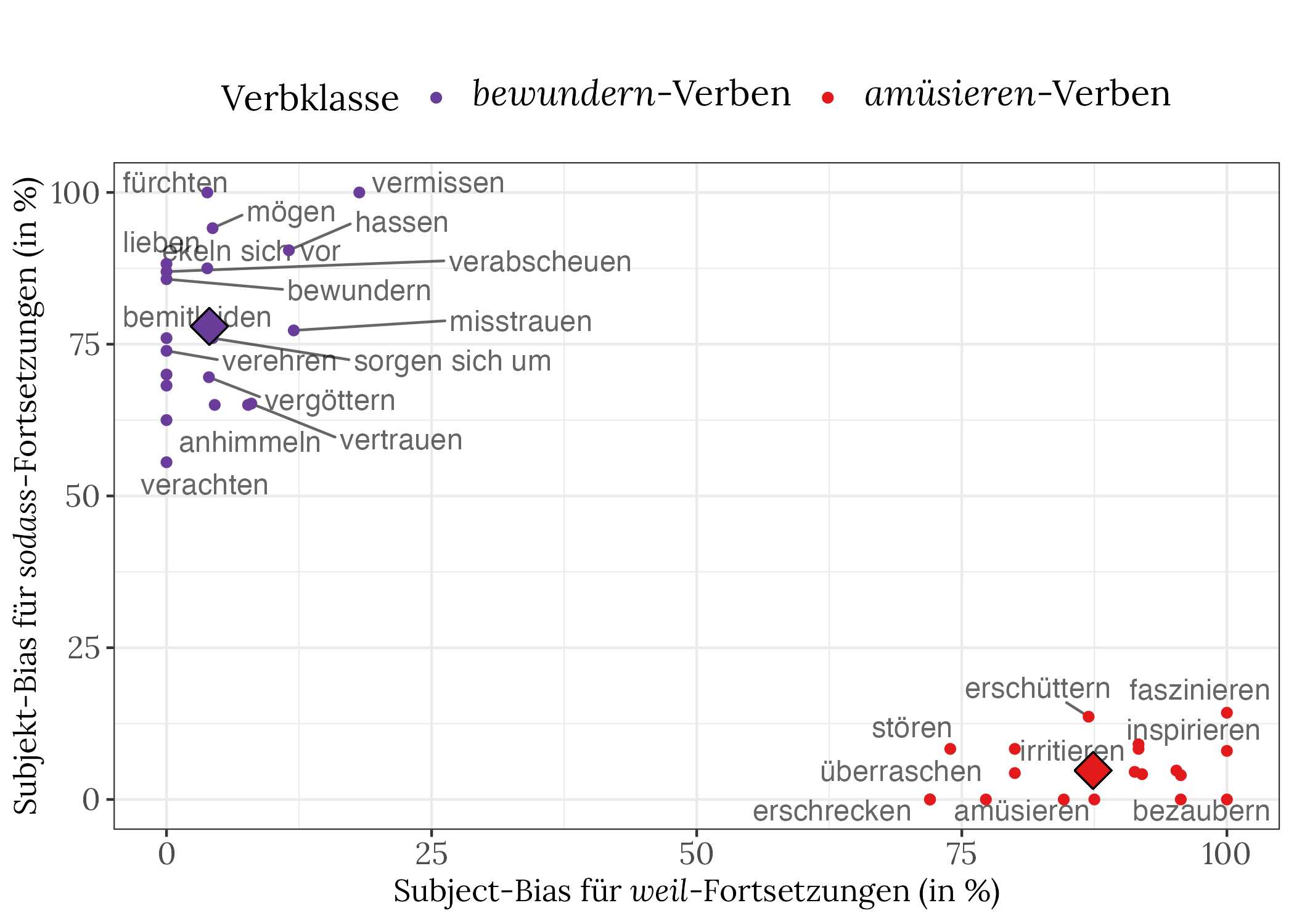
So ergeben sich bei Menschen klare Muster, wie die folgende Abbildung zeigt. Die amüsieren-Verben bilden eine Gruppe (unten rechts) mit Erklärungen über das Subjekt (hoher Subjekt-Bias auf der horizontalen Achse) und Konsequenzen über das Objekt (das heißt, niedriger Subjekt-Bias auf der vertikalen Achse). Die bewundern-Verben bilden ihrerseits eine zweite Gruppe (oben links) mit Objekt-Erklärungen und Subjekt-Konsequenzen. Die durchschnittlichen Präferenzen für die beiden Verbklassen sind durch einen großen Diamanten gekennzeichnet. Die Wolken sind natürlich nicht "perfekt", weil wir auch gegen das typische Muster verstoßen können, also eine Erklärung oder Konsequenz über die andere Person angeben können.
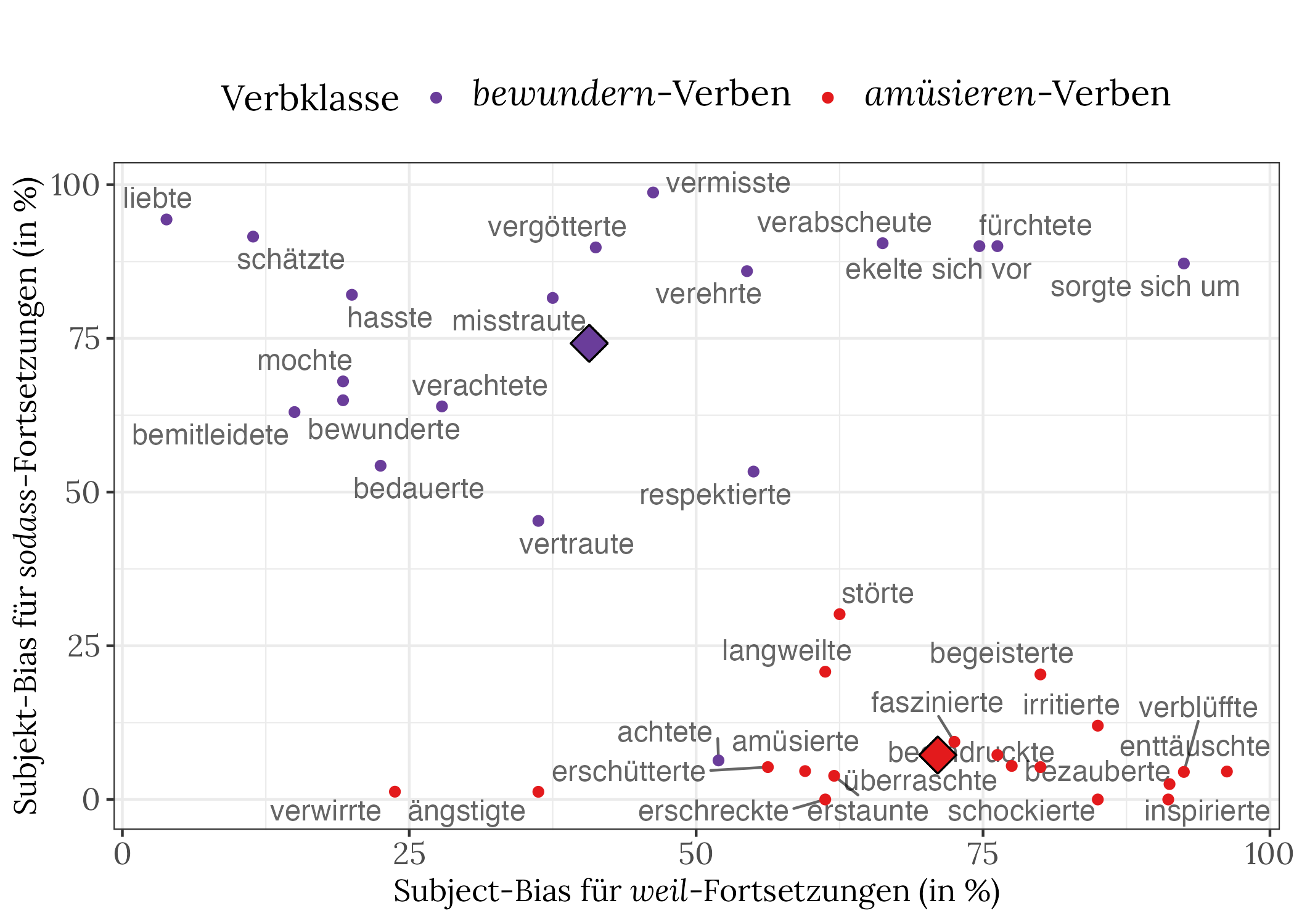
ChatGPT ist sogar besser als Menschen bei dieser Aufgabe, d. h. die "Verb-Wolken" sind noch mehr in den Ecken konzentriert (hier nicht gezeigt). Ein Sprachmodell wie Bloom, das kleiner und etwas anders funktioniert, zeigt aber kein so deutliches Bild, wie die Grafik unten zeigt. Hier sind die Wolken in Ansätzen erkennbar, aber mehr auch nicht. Wir sehen auch, dass die "Durchschnittsdiamanten" anders liegen als bei den Menschen.
Erklärungstypen und Vorwegnahme
Über den Subjekt- oder Objekt-Bias hinaus, ist es auch interessant, sich die genaueren Erklärungen anzusehen. In einem früheren Experiment haben wir untersucht, wie die Erklärungen für Verben wie amüsieren und bewundern als Ganzes aussehen – jenseits von dem Bias, etwas über das Subjekt oder Objekt zu schreiben. Es stellt sich heraus, dass man typisch etwas angibt, was genau das Gefühl ausgelöst hat, wie im amüsieren-Beispiel (hier wiederholt):
- Emma amüsierte Fritz, weil ... ✍ sie dauernd Witze erzählte.
Das ist eine Information, die im Satzprompt noch fehlt. Es ist so, also würden wir in der Fortsetzung die Frage beantworten: Was hat Emma gemacht? Oder was an ihr hat Fritz amüsiert?
Wie oben erwähnt, sind die Präferenzen / Biases nicht absolut. Wir können also gegen sie verstoßen. Wenn wir dies aber tun, geben wir typisch auch eine andere Erklärung:
- Emma amüsierte Fritz, weil ... ✍ er Witze mochte.
Hier können wir nur darauf schließen, dass Emma vermutlich Fritz amüsiert hat, indem sie Witze erzählt hat. Wichtig für uns ist jedoch, dass Bias – also die Präferenz über eine bestimmte Person etwas zu sagen – und Erklärungsart miteinander zusammenhängen.
Wir haben diese Annahme in einem weiteren Experiment auf die Probe gestellt und Vorgaben erstellt, in denen typische Erklärungen schon vorweggenommen wurden, wie bei
- Emma amüsierte Fritz durch das Erzählen von Witzen, weil ... ✍
Hier scheint es schwieriger zu sein, eine gute Erklärung zu geben und wir würden eher geneigt sein, den Satz wie in Beispiel 6 oben zu erklären (... ✍ weil er Witze mochte). Durch die Vorgabe wissen wir ja schon, wie Emma Fritz amüsiert hat!
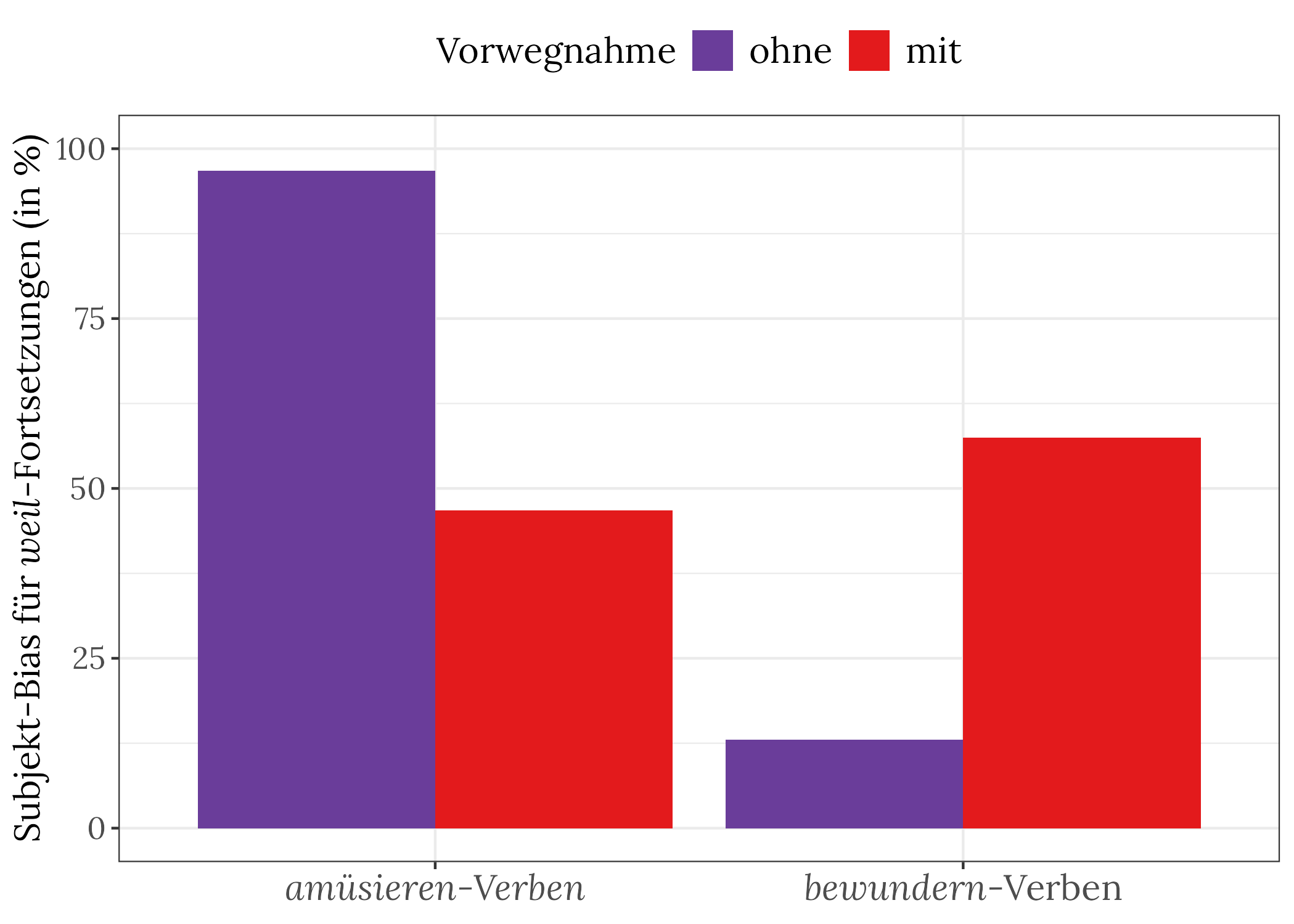
In der Grafik unten sehen wir, welchen Effekt solche "Erklärungsvorwegnahmen" auf den Bias haben. Die lila Balken zeigen die Präferenz ohne Vorwegnahme: amüsieren-Verben haben einen starken Subjekt-Bias, bewundern-Verben einen schwachen Subjekt-Bias, also einen Objekt-Bias – wie gehabt. Die roten Balken zeigen, was passiert, wenn wir Erklärungen vorwegnehmen: Beide Biases / Präferenzen verschieben sich – in die jeweils andere Richtung! In den Infos nach dem Urteilen 2-Quiz haben wir schon gezeigt, dass die Ergebnisse von ChatGPT hier nicht ganz so aussehen wie beim Menschen und dass Bloom diese Aufgabe nicht wirklich hinbekommt.
Da es hier auch um Feinheiten der Erklärungen geht, könnte man spekulieren, dass die Sprachmodelle womöglich die Satzvorgaben nicht so tief verstehen wie der Mensch.
Gemeinsam mit euch erforschen wir im laufenden Projekt, was die Erklärungen von Menschen und Maschinen auszeichnet. Insbesondere geht es uns darum zu untersuchen, was besonders kreative Erklärungen kennzeichnet. Dafür sind die Quiz-Daten und die Daten aus der Rolle Analysieren besonders interessant. Wir stehen mit der Forschungsreise noch am Anfang, aber mit jeder Fortsetzung und jedem Urteil, das Du beisteuerst, lernen wir mehr über die sprachliche Kreativität von Mensch und Maschine.
Darum bleib gespannt: Bald veröffentlichen wir erste Ergebnisse von der Spielwiese im Mensch-vs-Maschine-Forum, in dem du dich mit uns und anderen Usern austauschen kannst, um deine Erfahrungen zu teilen und Deine eigenen Hypothesen und Beobachtungen mit uns und anderen zu diskutieren!